📌 스펙트럼(Spectrum) 소리 신호를 주파수와 진폭으로 분석 푸리에 변환을 적용하여 시간 영역의 신호를 주파수 영역으로 변환 시간 영역 & 주파수 영역 시각화 (X축: 주파수, Y축: 진폭) https://ratsgo.github.io/speechbook/docs/fe/ft
📌 멜 스펙트로그램(Mel Spectrogram) 인간의 청각 영역을 반영한 Mel scale을 적용 - 인간은 보통 저주파를 더 잘 인식함
📌 MFCC(Mel-Frequency Cepstral Coefficient) 오디오 신호에서 추출할 수 있는 feature로, 소리의 고유한 특징을 나타내는 수치 스펙트로그램 생성 ➡️ Mel scale 적용 ➡️ 멜 스펙트로그램 생성 ➡️ 캡스트럴(Cepstral) 분석 ➡️ MFCC 특성 추출
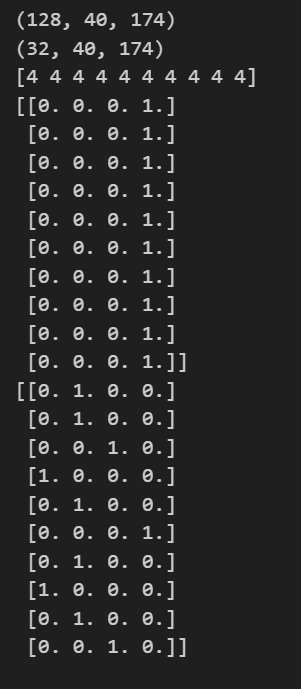
우선 저는 Overhead, Snare, Tom, Bass 데이터셋을 40개씩 준비하였습니다.
data는 리브로사로 추출한 특성 mfcc class_label은 그 드럼의 종류 (Overhead:1, Snare:2, Tom:3, Bass:4 임의로 정함) ➡️ 즉, 딥러닝이 분류할 클래스는 4가지
root_path = wav_파일들이_있는_폴더_path
wav_list = os.listdir(root_path)
wav_files = [os.path.join(root_path, file) for file in wav_list if file.endswith('.wav')]
print(len(wav_files))
features = []
for wav_file in wav_files:
# data는 리브로사로 추출한 mfccs라는 특성이고# class_label은 그 드럼의 종류를 나타낸다.
data = extract_feature(wav_file)
class_label = 0if'Overhead'in wav_file:
class_label = 1elif'Snare'in wav_file:
class_label = 2elif'Tom'in wav_file:
class_label = 3elif'Bass'in wav_file:
class_label = 4else:
class_label = 0
features.append([data, class_label])
# Convert into a Panda dataframe
featuresdf = pd.DataFrame(features, columns=['feature','class_label'])
featuresdf에 Panda 형태로 저장되었습니다!
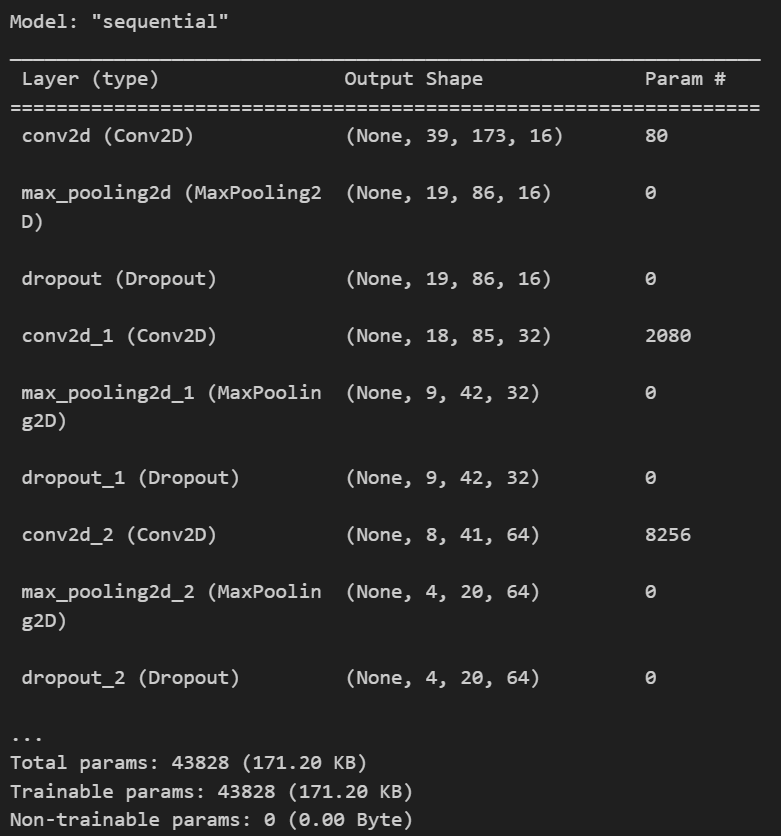
03. 훈련(Train), 검증(Test) Dataset 생성
featuresdf의 feature는 X로, class_label은 y로 저장합니다.
✨ 여기서 y는 one-hot-encoding 변환을 해야 합니다.
📌one-hot-encoding 예를 들어, 자연수 1, 2, 3 있을 때 1:[1.0.0] / 2:[0.1.0] / 3:[0.0.1] 이런 식으로 변환 이렇게 변환하는 이유는, 해당 글에서의 딥러닝 모델이 멀티 클래스(3~ 가지) 분류를 하기 때문 ➡️ 사람이 이해하기 쉬운 데이터를 컴퓨터가 이해하기 쉬운 데이터로 변환하는 기본적인 방법
from keras.utils import to_categorical
X = np.array(featuresdf.feature.tolist())
y = np.array(featuresdf.class_label.tolist())
le = LabelEncoder()
yy = to_categorical(le.fit_transform(y))